On Firefox on Android there is a reader mode that gives you just the text and images. It’s the little icon next to the url. Sometimes you can bypass a paywall if you press it really quick before the page finishes loading.
Lemme clarify a bit. I love reader mode too and agree it cuts out a lot of cruft.
My point was that authors and articles spend less time trying to write an engaging article and more time trying to shove SEO keywords and questions into articles. It ruins the article and makes it something not worth reading.
Reader mode is great but if the substance isn’t there then it’s all for naught.
Find one or two sites you regularly like from your usual sources. Then when THOSE sources link to another source, FOLLOW that link. If that site has good content, add it to your list.
It doesn’t take long to build a solid RSS feed, just need to spend a little time curating it. The key is to pay attention to who is providing the info.
Don’t like the direction a site is going, remove it from your feed.
If you see that one source is commonly the original source for information, or reporting make sure you do what you can to support it. Do they have a patreon? Can you share it out to your other sources?
Also, make sure you’re not falling into a bubble, follow national and international news sources.
I (tried to) remove all the local news sites, but this gives me a pretty decent overview of things I’m interested in, without being overwhelming. You should be able to find some local news sources, and add their LOCAL only feed, so you don’t get hammered with national and international news.
<outlinetext="ADHDinos"type="rss"xmlUrl="https://www.webtoons.com/en/challenge/adhdinos/rss?title_no=820817"htmlUrl="https://www.webtoons.com/en/canvas/adhdinos/list?title_no=820817"description="A webcomic about ADHD and the difficulties I've encountered through it. *No permission required for reposts*"/><outlinetext="Humon Comics"type="rss"xmlUrl="http://feeds.feedburner.com/Humon-Comics"htmlUrl="http://humoncomics.com"description="The latest issues."/><outlinetext="Order of the Stick"type="rss"xmlUrl="https://www.giantitp.com/comics/oots.rss"htmlUrl="http://www.giantitp.com/Comics.html"description="Order of the Stick"/><outlinetext="War and Peas"type="rss"xmlUrl="https://warandpeas.com/feed/"htmlUrl="https://warandpeas.com/"description="Funny Comics"/><outlinetext="Wondermark"type="rss"xmlUrl="https://wondermark.com/feed/"htmlUrl="https://wondermark.com/"description="An Illustrated Jocularity."/><outlinetext="XKCD"type="rss"xmlUrl="https://xkcd.com/atom.xml"htmlUrl="https://xkcd.com/"/><outlinetext="AnandTech"type="rss"xmlUrl="https://www.anandtech.com/rss/"htmlUrl="https://www.anandtech.com"description="This channel features the latest computer hardware related articles."/><outlinetext="Ars Technica - Logged In"type="rss"xmlUrl="https://arstechnica.com/feed/?t=d46cb9b3032ca6ca5789738f44a887d740740298"htmlUrl="https://arstechnica.com"description="Serving the Technologist since 1998. News, reviews, and analysis."/><outlinetext="BleepingComputer"type="rss"xmlUrl="https://www.bleepingcomputer.com/feed/"htmlUrl="https://www.bleepingcomputer.com/"description="BleepingComputer - All Stories"/><outlinetext="Bloody Disgusting!"type="rss"xmlUrl="http://feeds.feedburner.com/BloodyDisgusting"htmlUrl="https://bloody-disgusting.com/"description="Horror movie news, reviews, interviews, videos, podcasts and more"/><outlinetext="Deeplinks"type="rss"xmlUrl="https://www.eff.org/rss/updates.xml"htmlUrl="https://www.eff.org/rss/updates.xml"description="EFF's Deeplinks Blog: Noteworthy news from around the internet"/><outlinetext="iFixit"type="rss"xmlUrl="https://www.ifixit.com/News/rss"htmlUrl="https://valkyrie.ifixit.com"description="Fixing the world, one gizmo at a time."/><outlinetext="Krebs on Security"type="rss"xmlUrl="https://krebsonsecurity.com/feed/"htmlUrl="https://krebsonsecurity.com"description="In-depth security news and investigation"/><outlinetext="NPR Topics: News"type="rss"xmlUrl="https://feeds.npr.org/1001/rss.xml"htmlUrl="https://www.npr.org/templates/story/story.php?storyId=1001"description="NPR news, audio, and podcasts. Coverage of breaking stories, national and world news, politics, business, science, technology, and extended coverage of major national and world events."/><outlinetext="Schneier on Security"type="rss"xmlUrl="https://www.schneier.com/feed/atom/"htmlUrl="https://www.schneier.com"/><outlinetext="Science & Health – FiveThirtyEight"type="rss"xmlUrl="https://fivethirtyeight.com/science/feed/"htmlUrl="https://fivethirtyeight.com"description="FiveThirtyEight uses statistical analysis — hard numbers — to tell compelling stories about elections, politics and American society."/><outlinetext="The 19th"type="rss"xmlUrl="https://19thnews.org/feed/"htmlUrl="https://19thnews.org/"description="The 19th is an independent, nonprofit newsroom reporting at the intersection of gender, politics and policy."/><outlinetext="Universe Today"type="rss"xmlUrl="https://www.universetoday.com/feed/"htmlUrl="https://www.universetoday.com/"description="Space and astronomy news"/>
This is why I legit built my own space news app , because my autistic brain can’t handle all the crap they’ve added to pages. I just need the text, and images. I don’t need links to other articles in the body of the article! I’m currently reading this article!! and stop citing your own articles as sources!
I really agree - I’ve stepped away from reading so much of what’s online because it’s all clickbaity junk with no substance. I’m not sure where to look for actual content to put in my reader. But I’m making forays.

The problem I run into is most news sites optimize for 2 things
So most sites have a fuck ton of noise and carpet bomb ads.
I’d love to go back to the RSS model but it’s hard finding sites worth reading again.
On Firefox on Android there is a reader mode that gives you just the text and images. It’s the little icon next to the url. Sometimes you can bypass a paywall if you press it really quick before the page finishes loading.
Lemme clarify a bit. I love reader mode too and agree it cuts out a lot of cruft.
My point was that authors and articles spend less time trying to write an engaging article and more time trying to shove SEO keywords and questions into articles. It ruins the article and makes it something not worth reading.
Reader mode is great but if the substance isn’t there then it’s all for naught.
I use it quite often. Chills the eyes when reading. Standardized font(size) and design make this bearable.
Find one or two sites you regularly like from your usual sources. Then when THOSE sources link to another source, FOLLOW that link. If that site has good content, add it to your list.
It doesn’t take long to build a solid RSS feed, just need to spend a little time curating it. The key is to pay attention to who is providing the info.
Don’t like the direction a site is going, remove it from your feed.
If you see that one source is commonly the original source for information, or reporting make sure you do what you can to support it. Do they have a patreon? Can you share it out to your other sources?
Also, make sure you’re not falling into a bubble, follow national and international news sources.
I’d love to take a look at what other people are following and what they like about it. My own followed are kind of random.
Maybe this is one of those Qs a simple web search can answer…
Really hoping I don’t dox myself with this…
I (tried to) remove all the local news sites, but this gives me a pretty decent overview of things I’m interested in, without being overwhelming. You should be able to find some local news sources, and add their LOCAL only feed, so you don’t get hammered with national and international news.
<outline text="ADHDinos" type="rss" xmlUrl="https://www.webtoons.com/en/challenge/adhdinos/rss?title_no=820817" htmlUrl="https://www.webtoons.com/en/canvas/adhdinos/list?title_no=820817" description="A webcomic about ADHD and the difficulties I've encountered through it. *No permission required for reposts*"/> <outline text="Humon Comics" type="rss" xmlUrl="http://feeds.feedburner.com/Humon-Comics" htmlUrl="http://humoncomics.com" description="The latest issues."/> <outline text="Order of the Stick" type="rss" xmlUrl="https://www.giantitp.com/comics/oots.rss" htmlUrl="http://www.giantitp.com/Comics.html" description="Order of the Stick"/> <outline text="War and Peas" type="rss" xmlUrl="https://warandpeas.com/feed/" htmlUrl="https://warandpeas.com/" description="Funny Comics"/> <outline text="Wondermark" type="rss" xmlUrl="https://wondermark.com/feed/" htmlUrl="https://wondermark.com/" description="An Illustrated Jocularity."/> <outline text="XKCD" type="rss" xmlUrl="https://xkcd.com/atom.xml" htmlUrl="https://xkcd.com/"/> <outline text="AnandTech" type="rss" xmlUrl="https://www.anandtech.com/rss/" htmlUrl="https://www.anandtech.com" description="This channel features the latest computer hardware related articles."/> <outline text="Ars Technica - Logged In" type="rss" xmlUrl="https://arstechnica.com/feed/?t=d46cb9b3032ca6ca5789738f44a887d740740298" htmlUrl="https://arstechnica.com" description="Serving the Technologist since 1998. News, reviews, and analysis."/> <outline text="BleepingComputer" type="rss" xmlUrl="https://www.bleepingcomputer.com/feed/" htmlUrl="https://www.bleepingcomputer.com/" description="BleepingComputer - All Stories"/> <outline text="Bloody Disgusting!" type="rss" xmlUrl="http://feeds.feedburner.com/BloodyDisgusting" htmlUrl="https://bloody-disgusting.com/" description="Horror movie news, reviews, interviews, videos, podcasts and more"/> <outline text="Deeplinks" type="rss" xmlUrl="https://www.eff.org/rss/updates.xml" htmlUrl="https://www.eff.org/rss/updates.xml" description="EFF's Deeplinks Blog: Noteworthy news from around the internet"/> <outline text="iFixit" type="rss" xmlUrl="https://www.ifixit.com/News/rss" htmlUrl="https://valkyrie.ifixit.com" description="Fixing the world, one gizmo at a time."/> <outline text="Krebs on Security" type="rss" xmlUrl="https://krebsonsecurity.com/feed/" htmlUrl="https://krebsonsecurity.com" description="In-depth security news and investigation"/> <outline text="NPR Topics: News" type="rss" xmlUrl="https://feeds.npr.org/1001/rss.xml" htmlUrl="https://www.npr.org/templates/story/story.php?storyId=1001" description="NPR news, audio, and podcasts. Coverage of breaking stories, national and world news, politics, business, science, technology, and extended coverage of major national and world events."/> <outline text="Schneier on Security" type="rss" xmlUrl="https://www.schneier.com/feed/atom/" htmlUrl="https://www.schneier.com"/> <outline text="Science & Health – FiveThirtyEight" type="rss" xmlUrl="https://fivethirtyeight.com/science/feed/" htmlUrl="https://fivethirtyeight.com" description="FiveThirtyEight uses statistical analysis — hard numbers — to tell compelling stories about elections, politics and American society."/> <outline text="The 19th" type="rss" xmlUrl="https://19thnews.org/feed/" htmlUrl="https://19thnews.org/" description="The 19th is an independent, nonprofit newsroom reporting at the intersection of gender, politics and policy."/> <outline text="Universe Today" type="rss" xmlUrl="https://www.universetoday.com/feed/" htmlUrl="https://www.universetoday.com/" description="Space and astronomy news"/>This is why I legit built my own space news app , because my autistic brain can’t handle all the crap they’ve added to pages. I just need the text, and images. I don’t need links to other articles in the body of the article! I’m currently reading this article!! and stop citing your own articles as sources!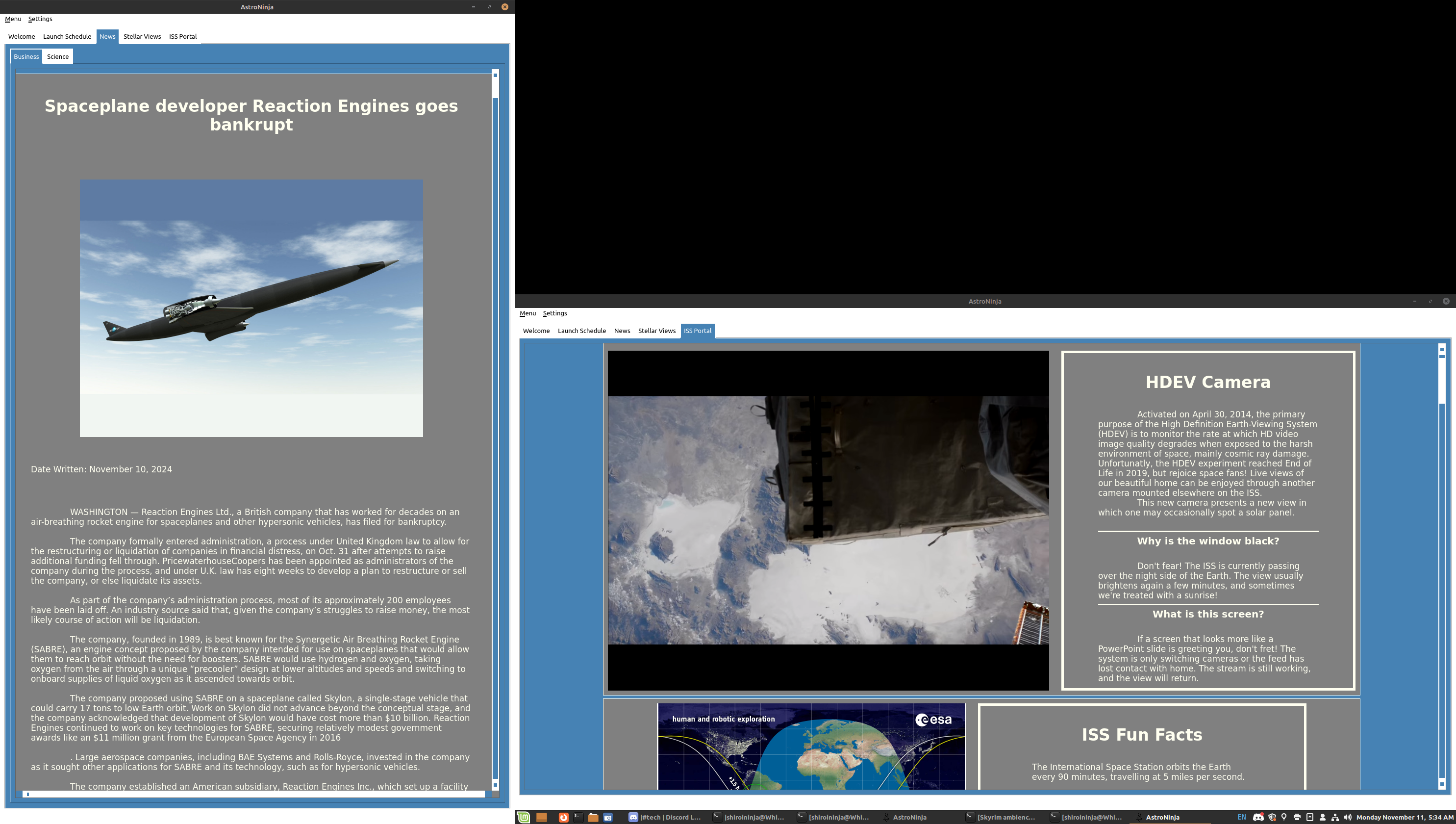
Yeah, is there some sort of directory or something? That’d be cool.
I really agree - I’ve stepped away from reading so much of what’s online because it’s all clickbaity junk with no substance. I’m not sure where to look for actual content to put in my reader. But I’m making forays.